Backed by Research, With Real Examples 🤓

A recent breakthrough paper titled “Principled Instructions Are All You Need for Questioning LLaMA-1/2, GPT-3.5/4” put prompt engineering to the test. The researchers evaluated 26 distinct prompt principles across 70B-parameter models and GPT-4, measuring their impact on correctness, quality, and conciseness.
The results were startling: well-engineered prompts didn’t just change the style—they improved response correctness by averages of 50% to 100% on specific tasks.
But here is the real takeaway for everyday users: not all principles are created equal. While the paper found that “politeness” (saying please and thank you) had a negligible 5% impact, other structural changes completely transformed the model’s output.
Below are the 10 principles with the strongest practical impact, integrated with the study’s specific findings and examples you can copy immediately.

1. Let the model ask clarifying questions
Research Insight: This was one of the highest-performing tactics in the study (Principle 14), showing a massive 100% improvement in correctness benchmarks for complex tasks. It shifts the dynamic from “guessing” to “consulting.”
Theory: LLMs are pattern recognizers, not mind readers. When a task is underspecified, they guess based on probability—leading to generic or inaccurate outputs. This principle (known as Interactive Prompting) forces the model to pause and gather the necessary state information before generating a solution.
Bad:
Create a workout plan for me.
Good:
I want a personalized workout plan. From now on, ask me questions to understand my fitness level, goals, and equipment before generating the plan.
2. State clear requirements
Research Insight: The study found that using keywords and strict regulations (Principle 25) prevents the model from “drifting” into generic conversational fillers.
Theory: LLMs optimize for the most statistically probable completion. Without constraints, they default to the “average” internet response. Requirements (keywords, tone, format, length) anchor the model to a specific output space, significantly reducing hallucination and irrelevance.
Bad:
Write a product review.
Good:
Write a 150–200 word review with these requirements: – Keywords: durable, affordable, eco-friendly – Must mention: battery life, build quality – Tone: professional but approachable
3. Copy the language/style of an example
Research Insight: Known as Few-Shot Prompting with style constraints (Principle 22), this method allows users to dictate nuance without explaining complex linguistic rules.
Theory: LLMs excel at imitation. When given a sample, they perform “in-context learning,” detecting patterns—sentence structure, tone, rhythm—and reproducing them with high precision. This is often more effective than describing the style (e.g., “witty” or “formal”) because the model can “see” the vector representation of the style directly.
Bad:
Write another product description for wireless earbuds.
Good:
Write a product description for wireless earbuds. Please use the same language style and sentence structure as the provided paragraph.
[Insert sample text here]
4. Ask for simple explanations
Research Insight: The paper identified Principle 5 (“Explain like I’m 11” or “beginner”) as a powerhouse for clarity, yielding an 85% improvement in response quality.
Theory: When you request simplicity, the model switches to compressed conceptual representations. This forces it to filter out jargon and complex sentence structures that often hide hallucinations or logic errors.
Bad:
Explain blockchain.
Good:
Explain blockchain as if I’m a beginner with no tech background. Use simple English.

5. Name the intended audience
Research Insight: Specifying the audience (Principle 2) was another top performer, showing a 100% improvement in relevant content generation in the study’s benchmarks.
Theory: Audience constraints determine the “perplexity” (complexity) of the output. If you don’t specify an audience, the model assumes a “general internet user.” By specifying “expert” or “child,” you adjust the model’s vocabulary, depth, and analogy selection instantly.
Bad:
Explain quantum computing.
Good:
Explain quantum computing to a high school student with no physics background.
6. Continue text with specific words or themes
Research Insight: Known as Output Priming (Principle 20/24), this technique improved accuracy by 75%. It works by “seeding” the response.
Theory: LLMs generate text token-by-token. By providing the first few words of the answer, you force the model down a specific probabilistic path. It acts like a railway switch, ensuring the train (the generation) starts on the right track.
Bad:
Continue this story: John walked into the room.
Good:
I am providing you with the beginning of a story: “John walked into the room.” Finish it based on the words provided. Keep the flow consistent. Use these keywords: mysterious, shadow, whisper.
7. Use prompts that test your understanding
Research Insight: This is Principle 15 in the paper (“Teach me… and include a test”). It turns the LLM from a passive search engine into an active tutor, improving retention and engagement scores.
Theory: Interactive learning creates a feedback loop. Instead of dumping information, the model must verify your input, which requires it to maintain a consistent “truth” state across multiple turns of conversation.
Bad:
Teach me photosynthesis.
Good:
Teach me photosynthesis. Then give me a short quiz. Don’t reveal the answers—wait for my response and tell me what I got right.
8. Use affirmative “do” statements
Research Insight: Principle 4 warns against negative constraints. Affirmative directives (“Do X”) outperformed negative ones (“Don’t do Y”) by reducing model confusion.
Theory: Negative instructions are cognitive load for a model. To “not do” something, the model often has to generate the concept internally and then suppress it. Positive directives steer the probabilistic distribution directly toward the desired tokens without requiring this suppression step.
Bad:
Don’t use jargon. Don’t make it long.
Good:
Give me a brief, simple-language explanation with only essential details.
9. Use “Your task is…” and “You MUST…”
Research Insight: Using strong directives like “You MUST” (Principle 9) resulted in a 75% improvement in adherence to constraints. It acts as a “soft” code injection, prioritizing the instruction over the training data’s general tendencies.
Theory: Phrases like “Your task is” create strong situational framing. They activate the model’s “instruction following” heads (parts of the neural network optimized during RLHF training), increasing focus and reducing irrelevant chit-chat.
Bad:
Can you summarize this article?
Good:
Your task is to summarize this article in exactly 3 sentences. You MUST include the main conclusion.
10. Assign a role to the model
Research Insight: Principle 16 (“Assign a role”) is one of the oldest but most effective tricks, improving quality by 60%.
Theory: LLMs utilize “personas” to context-switch. A “writer” persona accesses different vocabulary and logic patterns than a “coder” persona. Giving the model a role restricts the search space of possible words to those used by experts in that field.
Bad:
Rewrite my resume.
Good:
You are a career coach with 15 years of experience. Help me improve my resume for a project management role.
Bonus Principle: Use step-by-step reasoning
Research Insight: While well-known, Principle 12 (“Think step by step”) remains essential for logic and math, reliably improving accuracy by 50% or more.
Theory: This activates Chain-of-Thought (CoT) processing. By generating intermediate steps, the model gives itself more “compute time” (more tokens) to resolve logic before committing to a final answer.
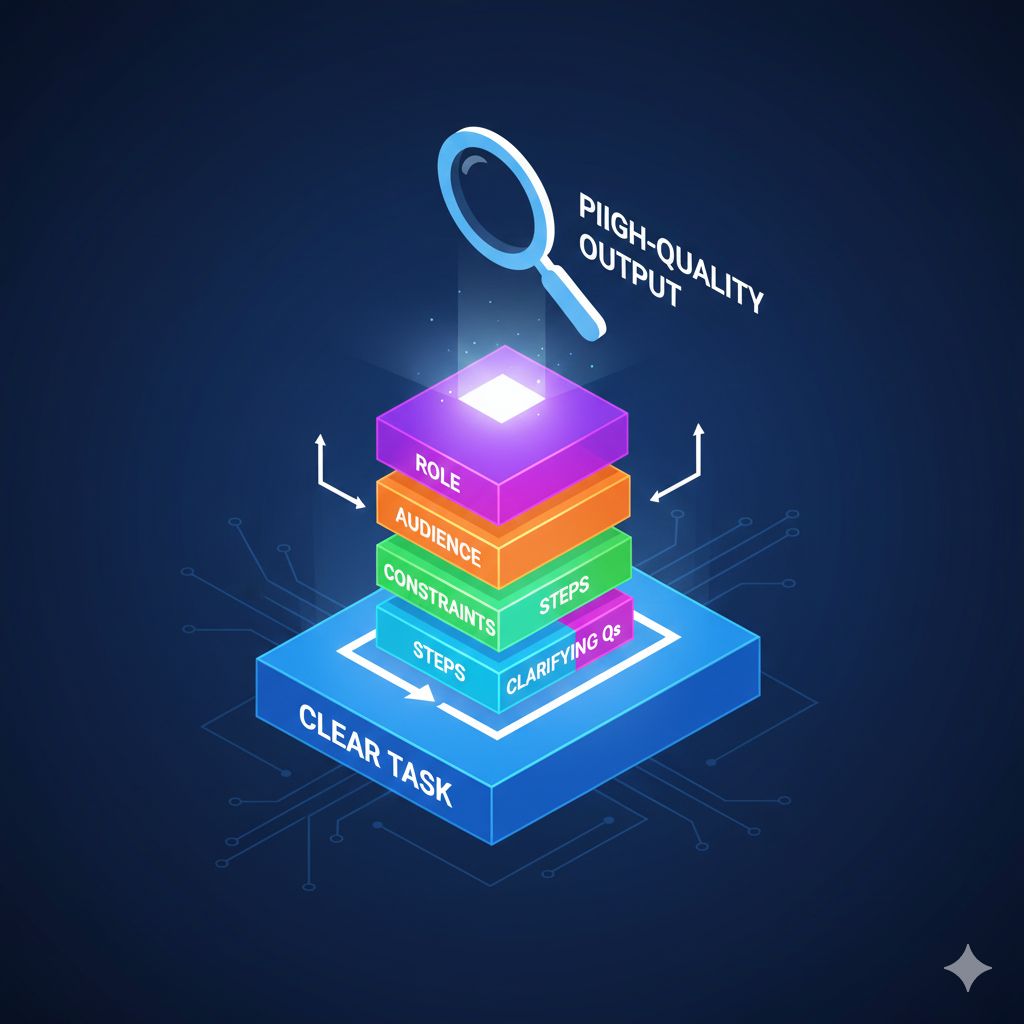
Putting it all together: The "Mega-Prompt"
Here is how you combine the highest-impact principles (Roles, Tasks, Clarification, and Audience) into a single, research-backed super prompt:
(Principle 16 & 9) You are a senior UX designer. Your task is to audit the signup flow of a mobile app.
(Principle 25 & 4) You MUST provide actionable recommendations. Focus on clarity and ease of use.
(Principle 5) Explain the findings in simple terms for a non-designer audience.
(Principle 14) Before giving your audit, ask me any clarifying questions you need regarding the app’s target user.
(Principle 2) Follow this structure: Overview → Pain Points → Recommendations. Length: 300–400 words.
Make the first step and enjoy the journey!

- No limited trial period
- No upfront payment
- No automatic renewal
- No hidden costs